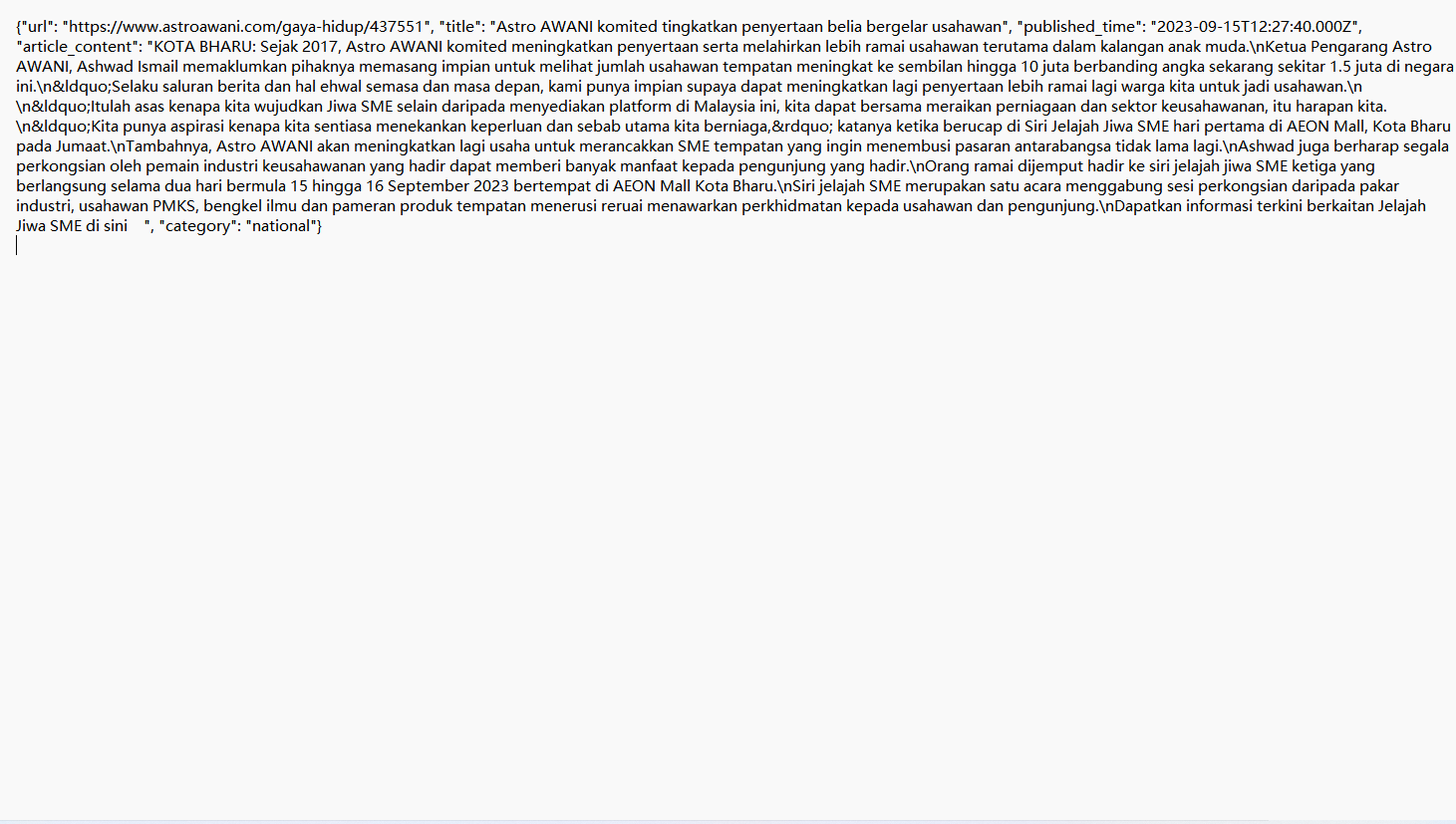
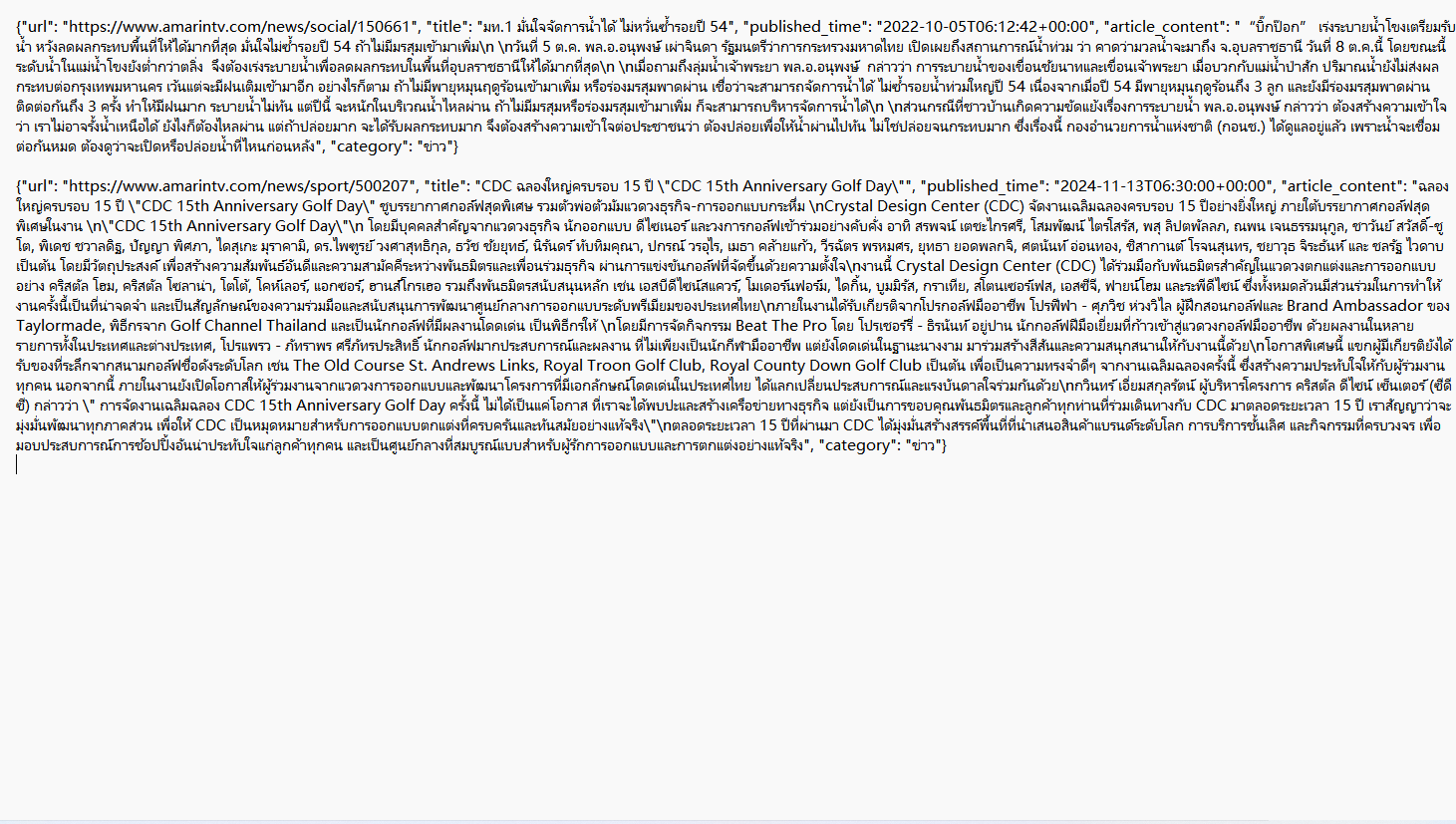
[{"@type":"PropertyValue","name":"Languages","value":"Indonesian, Malay, Thai, Vietnamese"},{"@type":"PropertyValue","name":"Data volume","value":"14447771 Indonesian, 1239420 Malay, 6467564 Thai, 8942813 Vietnamese, with a total of over 31 million pieces"},{"@type":"PropertyValue","name":"Field","value":"URL,title,published_time,article_content,category"},{"@type":"PropertyValue","name":"Format","value":"JSONL"}]
{"id":1625,"datatype":"1","titleimg":"https://www.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp","type1":"226","type1str":null,"type2":"227","type2str":null,"dataname":"31 Million Southeast Asian News Text Dataset – 4 Languages for AI","datazy":[{"title":"Languages","content":"Indonesian, Malay, Thai, Vietnamese","desc":"Languages"},{"title":"Data volume","content":"14447771 Indonesian, 1239420 Malay, 6467564 Thai, 8942813 Vietnamese, with a total of over 31 million pieces","desc":"Data volume"},{"title":"Field","content":"URL,title,published_time,article_content,category","desc":"Field"},{"title":"Format","content":"JSONL","desc":"Format"}],"datatag":"Minor languages,Southeast Asia,NEWS,Journalism","technologydoc":null,"downurl":null,"datainfo":null,"standard":null,"dataylurl":null,"flag":null,"publishtime":null,"createby":null,"createtime":null,"ext1":null,"samplestoreloc":null,"hosturl":null,"datasize":null,"industryPlan":null,"keyInformation":"","samplePresentation":[{"name":"马来语样例.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E9%A9%AC%E6%9D%A5%E8%AF%AD%E6%A0%B7%E4%BE%8B.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=5rkbhwPKFeZUofOfpzcAP1%2B7Vas%3D","intro":"","size":44215,"progress":100,"type":"jpg"},{"name":"泰语样例.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E6%B3%B0%E8%AF%AD%E6%A0%B7%E4%BE%8B.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=1DspN1HLIWVpn%2FYfI6JAu0ZMbl0%3D","intro":"","size":103642,"progress":100,"type":"jpg"},{"name":"印尼语样例.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E5%8D%B0%E5%B0%BC%E8%AF%AD%E6%A0%B7%E4%BE%8B.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=VgoGApYUn6%2BChZRcnvN08SYI8cU%3D","intro":"","size":115113,"progress":100,"type":"jpg"}],"officialSummary":"The 31 Million Southeast Asian Language News Text Dataset contains multilingual news articles across Indonesian, Malay, Thai, and Vietnamese. The total amount of data exceeds 31 million, stored in JSONL format, with each record running independently in a row for efficient reading and processing. The data sources are extensive, covering various news topics, and can comprehensively reflect the social dynamics, cultural hotspots, and economic trends in Southeast Asia. This dataset can help multilingual AI training, and cross-linguistic model development, enrich cultural knowledge, optimize performance, expand industry applications in Southeast Asia, and promote cross linguistic research.","dataexampl":null,"datakeyword":["Southeast Asian dataset","multilingual news dataset","Indonesian text dataset","Malay news corpus","Thai language dataset","Vietnamese text dataset","AI training data Southeast Asia","multilingual text corpu","large-scale news dataset"],"isDelete":null,"ids":null,"idsList":null,"datasetCode":null,"productStatus":null,"tagTypeEn":"Type","tagTypeZh":null,"website":null,"samplePresentationList":null,"datazyList":null,"keyInformationList":null,"dataexamplList":null,"bgimg":null,"datazyScriptList":null,"datakeywordListString":null,"sourceShowPage":"llm","dataShowType":"[{\"code\":\"0\",\"language\":\"ZH\"},{\"code\":\"1\",\"language\":\"ZH\"},{\"code\":\"2\",\"language\":\"EN,PT,DE,KO,FR,ES\"},{\"code\":\"3\",\"language\":\"EN\"}]","productNameEn":"31 million Southeast Asian language news text dataset","BGimg":"","voiceBg":["/shujutang/static/image/comm/audio_bg.webp","/shujutang/static/image/comm/audio_bg2.webp","/shujutang/static/image/comm/audio_bg3.webp","/shujutang/static/image/comm/audio_bg4.webp","/shujutang/static/image/comm/audio_bg5.webp"],"firstList":[{"name":"越南语样例.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E8%B6%8A%E5%8D%97%E8%AF%AD%E6%A0%B7%E4%BE%8B.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=HZvCPn1N1QW%2BocWDBvsxQJcoJzc%3D","intro":"","size":108698,"progress":100,"type":"jpg"}]}
https://www.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp
[{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E9%A9%AC%E6%9D%A5%E8%AF%AD%E6%A0%B7%E4%BE%8B.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=5rkbhwPKFeZUofOfpzcAP1%2B7Vas%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E6%B3%B0%E8%AF%AD%E6%A0%B7%E4%BE%8B.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=1DspN1HLIWVpn%2FYfI6JAu0ZMbl0%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E5%8D%B0%E5%B0%BC%E8%AF%AD%E6%A0%B7%E4%BE%8B.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=VgoGApYUn6%2BChZRcnvN08SYI8cU%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E8%B6%8A%E5%8D%97%E8%AF%AD%E6%A0%B7%E4%BE%8B.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=HZvCPn1N1QW%2BocWDBvsxQJcoJzc%3D"}]
31 Million Southeast Asian News Text Dataset – 4 Languages for AI
Southeast Asian dataset
multilingual news dataset
Indonesian text dataset
Malay news corpus
Thai language dataset
Vietnamese text dataset
AI training data Southeast Asia
multilingual text corpu
large-scale news dataset
The 31 Million Southeast Asian Language News Text Dataset contains multilingual news articles across Indonesian, Malay, Thai, and Vietnamese. The total amount of data exceeds 31 million, stored in JSONL format, with each record running independently in a row for efficient reading and processing. The data sources are extensive, covering various news topics, and can comprehensively reflect the social dynamics, cultural hotspots, and economic trends in Southeast Asia. This dataset can help multilingual AI training, and cross-linguistic model development, enrich cultural knowledge, optimize performance, expand industry applications in Southeast Asia, and promote cross linguistic research.
This is a paid datasets for commercial use, research purpose and more. Licensed ready made datasets help jump-start AI projects.
![Specifications]()
Specifications
Languages
Indonesian, Malay, Thai, Vietnamese
Data volume
14447771 Indonesian, 1239420 Malay, 6467564 Thai, 8942813 Vietnamese, with a total of over 31 million pieces
Field
URL,title,published_time,article_content,category
![Sample]()
Sample
Tell Us Your Special Needs
254c5a98-fe0e-4b5f-8081-db56657d35d4





 Specifications
Specifications Sample
Sample