[{"@type":"PropertyValue","name":"Content","value":"OKWAVE Q&A text data, the platform authorization and copyright are clear;"},{"@type":"PropertyValue","name":"Data Size","value":"The data is continuously updated. As of the end of April 25, there were 8.4 million questions and 2.3 billion words. 27 million answers and 7.6 billion words; Thanks (the gratitude expressed by the questioner to the responder) 15.5 million pieces, 1.7 billion words; Supplementary explanations amount to 2.1 million pieces, totaling 360 million words;"},{"@type":"PropertyValue","name":"Data fields","value":"Contains question, answer, category, create_datetime, user, etc;"},{"@type":"PropertyValue","name":"Storage Format","value":"Json"},{"@type":"PropertyValue","name":"Language","value":"Japanese"}]
{"id":1840,"datatype":"1","titleimg":"https://www.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp","type1":"226","type1str":null,"type2":"227","type2str":null,"dataname":"Japanese Q&A Dataset from OKWAVE – 8.4M Questions","datazy":[{"title":"Content","content":"OKWAVE Q&A text data, the platform authorization and copyright are clear;","desc":"Content"},{"title":"Data Size","content":"The data is continuously updated. As of the end of April 25, there were 8.4 million questions and 2.3 billion words. 27 million answers and 7.6 billion words; Thanks (the gratitude expressed by the questioner to the responder) 15.5 million pieces, 1.7 billion words; Supplementary explanations amount to 2.1 million pieces, totaling 360 million words;","desc":"Data Size"},{"title":"Data fields","content":"Contains question, answer, category, create_datetime, user, etc;","desc":"Data fields"},{"title":"Storage Format","content":"Json","desc":"Storage Format"},{"title":"Language","content":"Japanese","desc":"Language"}],"datatag":"Q&A,Text,Japanese","technologydoc":null,"downurl":null,"datainfo":null,"standard":null,"dataylurl":null,"flag":null,"publishtime":null,"createby":null,"createtime":null,"ext1":null,"samplestoreloc":null,"hosturl":null,"datasize":null,"industryPlan":null,"keyInformation":"","samplePresentation":[{"name":"1.png","url":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/1.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=suJVU5qEJZI7cFfSmGbb%2FEH3O%2Fc%3D","intro":"","size":93090,"progress":100,"type":"jpg"},{"name":"2.png","url":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/2.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=8VyLeLdVdYOPK5uOxWCTPVy%2B17k%3D","intro":"","size":138876,"progress":100,"type":"jpg"},{"name":"3.png","url":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/3.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=TfchG2iN3SSpSSlkWCnK%2FwdA2Qw%3D","intro":"","size":87528,"progress":100,"type":"jpg"}],"officialSummary":"This dataset is collected from the Japanese OKWAVE Q&A platform and includes large-scale parsed and processed text data suitable for LLM training and Japanese natural language understanding. It contains structured fields such as questions, answers, categories, timestamps, user metadata, and supplementary explanations. As of April 2025, the dataset includes 8.4 million questions with 2.3 billion words, 27 million answers totaling 7.6 billion words, 15.5 million thank-you messages (1.7 billion words), and 2.1 million supplementary replies (360 million words). Continuously updated and rich in user-generated content, this dataset is ideal for building Japanese conversational AI, ChatGPT fine-tuning, question answering systems, text summarization, and semantic parsing models. All data complies with relevant data usage and privacy regulations.","dataexampl":null,"datakeyword":["Japanese Q&A dataset","OKWAVE forum data","Japanese language corpus","Japanese dialogue dataset","ChatGPT Japanese fine-tuning","user-generated content","question answer dataset"],"isDelete":null,"ids":null,"idsList":null,"datasetCode":null,"productStatus":null,"tagTypeEn":"Type","tagTypeZh":null,"website":null,"samplePresentationList":null,"datazyList":null,"keyInformationList":null,"dataexamplList":null,"bgimg":null,"datazyScriptList":null,"datakeywordListString":null,"sourceShowPage":"llm","dataShowType":"[{\"code\":\"1\",\"language\":\"ZH\"},{\"code\":\"2\",\"language\":\"EN,JP,PT,DE,KO,FR,ES\"},{\"code\":\"3\",\"language\":\"EN\"},{\"code\":\"4\",\"language\":\"JP\"}]","productNameEn":"Japanese OKWAVE Q&A platform Text Parsing and Processing Data","BGimg":"","voiceBg":["/shujutang/static/image/comm/audio_bg.webp","/shujutang/static/image/comm/audio_bg2.webp","/shujutang/static/image/comm/audio_bg3.webp","/shujutang/static/image/comm/audio_bg4.webp","/shujutang/static/image/comm/audio_bg5.webp"]}
https://www.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp
[{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/1.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=suJVU5qEJZI7cFfSmGbb%2FEH3O%2Fc%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/2.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=8VyLeLdVdYOPK5uOxWCTPVy%2B17k%3D"},{"@type":"ImageObject","embedUrl":"https://storage-product.datatang.com/damp/product/sample_presentation/20251013133323/3.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=TfchG2iN3SSpSSlkWCnK%2FwdA2Qw%3D"}]
Japanese Q&A Dataset from OKWAVE – 8.4M Questions
Japanese Q&A dataset
OKWAVE forum data
Japanese language corpus
Japanese dialogue dataset
ChatGPT Japanese fine-tuning
user-generated content
question answer dataset
This dataset is collected from the Japanese OKWAVE Q&A platform and includes large-scale parsed and processed text data suitable for LLM training and Japanese natural language understanding. It contains structured fields such as questions, answers, categories, timestamps, user metadata, and supplementary explanations. As of April 2025, the dataset includes 8.4 million questions with 2.3 billion words, 27 million answers totaling 7.6 billion words, 15.5 million thank-you messages (1.7 billion words), and 2.1 million supplementary replies (360 million words). Continuously updated and rich in user-generated content, this dataset is ideal for building Japanese conversational AI, ChatGPT fine-tuning, question answering systems, text summarization, and semantic parsing models. All data complies with relevant data usage and privacy regulations.
This is a paid datasets for commercial use, research purpose and more. Licensed ready made datasets help jump-start AI projects.
![Specifications]()
Specifications
Content
OKWAVE Q&A text data, the platform authorization and copyright are clear;
Data Size
The data is continuously updated. As of the end of April 25, there were 8.4 million questions and 2.3 billion words. 27 million answers and 7.6 billion words; Thanks (the gratitude expressed by the questioner to the responder) 15.5 million pieces, 1.7 billion words; Supplementary explanations amount to 2.1 million pieces, totaling 360 million words;
Data fields
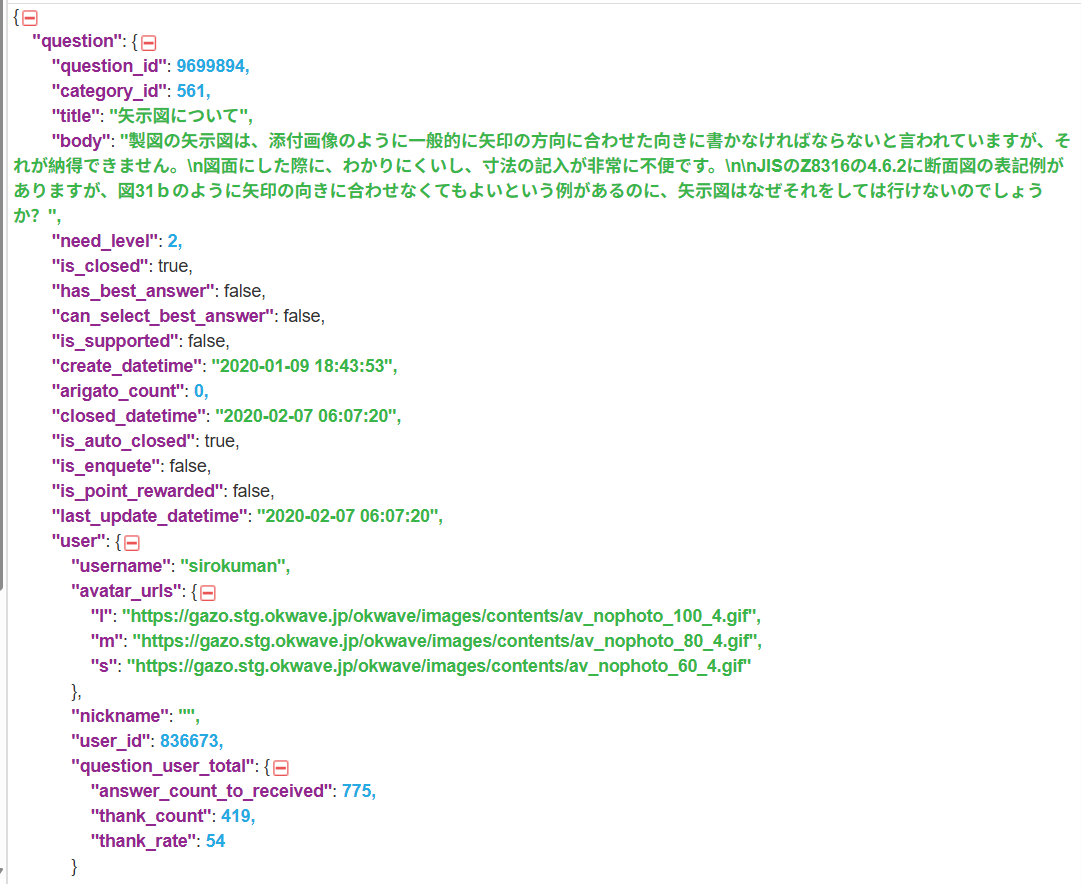
Contains question, answer, category, create_datetime, user, etc;
![Sample]()
Sample
![Recommended Datasets]()
Recommended Dataset
Tell Us Your Special Needs
539aca1d-bacd-4ae2-80b6-dbdbccfbc45f





 Specifications
Specifications Sample
Sample

 Recommended Dataset
Recommended Dataset




