[{"@type":"PropertyValue","name":"Data content","value":"200000 pieces of text content in French, German, Spanish, and Italian"},{"@type":"PropertyValue","name":"Category","value":"covering more than 200 categories such as architecture, animals, automobiles, catering, movies, constellations, cybersecurity, etc"},{"@type":"PropertyValue","name":"Data volume","value":"50000 pieces each for French, German, Spanish, and Italian"},{"@type":"PropertyValue","name":"Languages","value":"French, German, Spanish, Italian"},{"@type":"PropertyValue","name":"Field","value":"contents,category"},{"@type":"PropertyValue","name":"Format","value":"json"}]
{"id":1514,"datatype":"1","titleimg":"https://www.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp","type1":"226","type1str":null,"type2":"227","type2str":null,"dataname":"200,000 Multilingual Text Dataset in French, German, Spanish & Italian for NLP Training","datazy":[{"title":"Data content","content":"200000 pieces of text content in French, German, Spanish, and Italian","desc":"Data content"},{"title":"Category","content":"covering more than 200 categories such as architecture, animals, automobiles, catering, movies, constellations, cybersecurity, etc","desc":"Category"},{"title":"Data volume","content":"50000 pieces each for French, German, Spanish, and Italian","desc":"Data volume"},{"title":"Languages","content":"French, German, Spanish, Italian","desc":"Languages"},{"title":"Field","content":"contents,category","desc":"Field"},{"title":"Format","content":"json","desc":"Format"}],"datatag":"Network Data,German, French, Spanish, Italian","technologydoc":null,"downurl":null,"datainfo":null,"standard":null,"dataylurl":null,"flag":null,"publishtime":null,"createby":null,"createtime":null,"ext1":null,"samplestoreloc":null,"hosturl":null,"datasize":null,"industryPlan":null,"keyInformation":"","samplePresentation":[{"name":"德语.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E5%BE%B7%E8%AF%AD.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=Lt0IZkNRx6mg4wOEnhcb5NdEcmU%3D","intro":"","size":27326,"progress":100,"type":"jpg"},{"name":"法语.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E6%B3%95%E8%AF%AD.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=Q%2FBFyBvTvdUbH0K4B2lnwjIUgE8%3D","intro":"","size":26410,"progress":100,"type":"jpg"},{"name":"西班牙语.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E8%A5%BF%E7%8F%AD%E7%89%99%E8%AF%AD.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=xFYU8Jtl%2F%2B5PGtdm1TZQ0Tot%2F7A%3D","intro":"","size":23874,"progress":100,"type":"jpg"}],"officialSummary":"This dataset contains 200,000 pieces of high-quality multilingual text content, evenly distributed across four languages: French, German, Spanish, and Italian (50,000 per language). The text samples span over 200 categories such as architecture, animals, automobiles, food & beverage, movies, zodiac signs, and cybersecurity. Designed to support a variety of natural language processing (NLP) tasks, this dataset is ideal for multilingual language model fine-tuning, cross-lingual classification, machine translation, and generative AI applications. All content is clean, well-formatted, and suitable for commercial and academic AI research.","dataexampl":null,"datakeyword":["multilingual text dataset","French text dataset","German text dataset","Spanish text dataset","Italian text data","NLP multilingual training","language model fine-tuning","categorized text dataset","LLM training data","multilingual corpus"],"isDelete":null,"ids":null,"idsList":null,"datasetCode":null,"productStatus":null,"tagTypeEn":"Type","tagTypeZh":null,"website":null,"samplePresentationList":null,"datazyList":null,"keyInformationList":null,"dataexamplList":null,"bgimg":null,"datazyScriptList":null,"datakeywordListString":null,"sourceShowPage":"llm","dataShowType":"[{\"code\":\"0\",\"language\":\"ZH\"},{\"code\":\"1\",\"language\":\"ZH\"},{\"code\":\"2\",\"language\":\"EN,PT,DE,KO,FR,ES\"},{\"code\":\"3\",\"language\":\"EN\"},{\"code\":\"4\",\"language\":\"JP\"}]","productNameEn":"200000 text data in German, Spanish, French, and Italian","BGimg":"","voiceBg":["/shujutang/static/image/comm/audio_bg.webp","/shujutang/static/image/comm/audio_bg2.webp","/shujutang/static/image/comm/audio_bg3.webp","/shujutang/static/image/comm/audio_bg4.webp","/shujutang/static/image/comm/audio_bg5.webp"],"firstList":[{"name":"意大利语.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E6%84%8F%E5%A4%A7%E5%88%A9%E8%AF%AD.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=wetCJjJuZysFpR%2FYpd2FRzdClEE%3D","intro":"","size":23350,"progress":100,"type":"jpg"}]}
200,000 Multilingual Text Dataset in French, German, Spanish & Italian for NLP Training
multilingual text dataset
French text dataset
German text dataset
Spanish text dataset
Italian text data
NLP multilingual training
language model fine-tuning
categorized text dataset
LLM training data
multilingual corpus
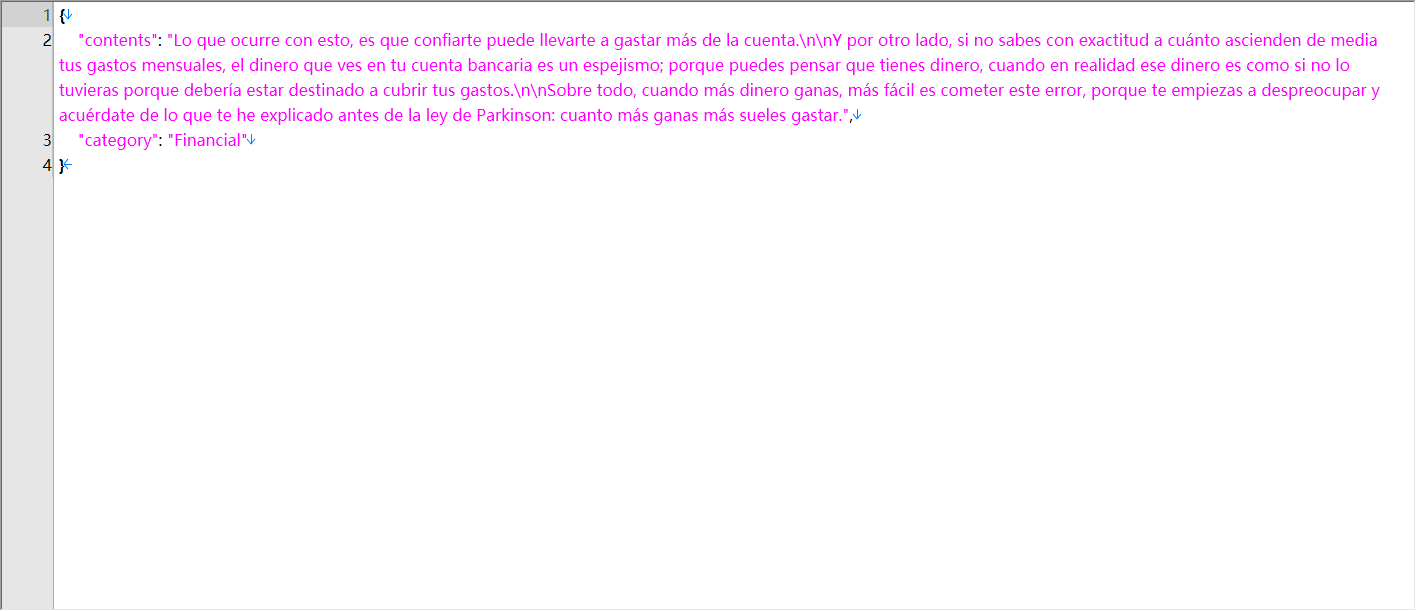
This dataset contains 200,000 pieces of high-quality multilingual text content, evenly distributed across four languages: French, German, Spanish, and Italian (50,000 per language). The text samples span over 200 categories such as architecture, animals, automobiles, food & beverage, movies, zodiac signs, and cybersecurity. Designed to support a variety of natural language processing (NLP) tasks, this dataset is ideal for multilingual language model fine-tuning, cross-lingual classification, machine translation, and generative AI applications. All content is clean, well-formatted, and suitable for commercial and academic AI research.
This is a paid datasets for commercial use, research purpose and more. Licensed ready made datasets help jump-start AI projects.
Specifications
Data content
200000 pieces of text content in French, German, Spanish, and Italian
Category
covering more than 200 categories such as architecture, animals, automobiles, catering, movies, constellations, cybersecurity, etc
Data volume
50000 pieces each for French, German, Spanish, and Italian





 Specifications
Specifications Sample
Sample

 Recommended Dataset
Recommended Dataset




